|
Data Mining Processes
Traditionally, there have been two types of statistical analyses: confirmatory analysis and exploratory analysis. In confirmatory analysis, one has a hypothesis and either confirms or refutes it. However, the bottleneck for confirmatory analysis is the shortage of hypotheses on the part of the analyst. In "exploratory analysis", (Tukey, 1973), one finds suitable hypotheses to confirm or refute. Here the system takes the initiative in data analysis, not the user.
The concept of "initiative" also applies to multidimensional spaces. In a simple OLAP access system, the user may have to think of a hypothesis and generate a graph. But in OLAP data mining, the system thinks of the questions by itself (Parsaye, 1997). I use the term data mining to refer to the automated process of data analysis in which the system takes the initiative to generate patterns by itself.
From a process oriented view, there are three classes of data mining activity: discovery, predictive modeling and forensic analysis, as shown in Figure1.
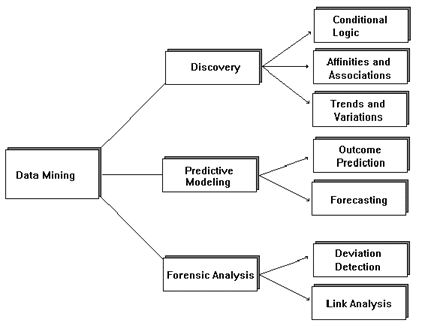
Figure 1.
Discovery is the process of looking in a database to find hidden patterns without a predetermined idea or hypothesis about what the patterns may be. In other words, the program takes the initiative in finding what the interesting patterns are, without the user thinking of the relevant questions first. In large databases, there are so many patterns that the user can never practically think of the right questions to ask. The key issue here is the richness of the patterns that can be expressed and discovered and the quality of the information delivered -- determining the power and usefulness of the discovery technique.
As a simple example of discovery with system initiative, suppose we have a demographic database of the US. The user may take the initiative to ask a question from the database, such as "what is the average age of bankers?" The system may then print 47 as the average age. The user may then ask the system to take the initiative and find something interesting about "age" by itself. The system will then act as a human analyst would. It will look at some data characteristics, distributions, etc. and try to find some data densities that might be away from ordinary. In this case the system may print the rule: "IF Profession = Athlete THEN Age < 30, with a 71% confidence." This rule means that if we pick 100 athletes from the database, 71 of them are likely to be under 30. The system may also print: "IF Profession = Athlete THEN Age < 60, with a 97% confidence." This rule means that if we pick 100 athletes from the database, 97 of them are likely to be under 60. This delivers information to the user by distilling pattern from data.
In predictive modeling patterns discovered from the database are used to predict the future. Predictive modeling thus allows the user to submit records with some unknown field values, and the system will guess the unknown values based on previous patterns discovered from the database. While discovery finds patterns in data, predictive modeling applies the patterns to guess values for new data items.
To use the example above, once we know that athletes are usually under 30, we can guess someone's age if we know that they are an athlete. For instance, if we are shown a record for John Smith whose profession is athlete by applying the rules we found above, we can be over 70% sure that he is under 30 years old, and we can be almost certain that he is under 60. Note that discovery helps us find "general knowledge," but prediction just guesses the value for the age of a specific individual. Also note that in this case the prediction is "transparent" (i.e., we know why we guess the age as under 30). In some systems the age is guessed, but the reason for the guess is not provided, making the system "opaque."
Forensic analysis is the process of applying the extracted patterns to find anomalous, or unusual data elements. To discover the unusual, we first find what is the norm, then we detect those items that deviate from the usual within a given threshold. Again, to use the example above, once we notice that 97% of athletes are under 60, we can wonder about the 3% who are over 60 and still listed as athletes. These are unusual, but we still do not know why. They may be unusually healthy or play sports where age is less important (e.g., golf) or the database may contain errors, etc. Note that discovery helps us find "usual knowledge," but forensic analysis looks for unusual and specific cases.
Each of these processes can be further classified. There are several types of pattern discovery such as If/Then rules, associations, etc. While the rules discussed above have an IF-THEN nature, association rules refer to items groupings (e.g., when someone buys one product at a store, they may buy other product at the same time -- a process usually called market basket analysis). The power of a discovery system is measured by the types and generality of the patterns it can find and express in a suitable language.
Data Mining Users and Activities
It is necessary to distinguish the data mining processes discussed above from the data mining activities in which the processes may be performed, and the users who perform them. First, the users. Data mining activities are usually performed by three different classes of users: executives, end users and analysts.
Executives need top-level insights and spend far less time with computers than the other groups -- their attention span is usually less than 30 minutes. They may want information beyond what is available in their executive information system (EIS). Executives are usually assisted by end users and analysts.
End users know how to use a spreadsheet, but they do not program -- they can spend several hours a day with computers. Examples of end users are sales people, market researchers, scientists, engineers, physicians, etc. At times, managers assume the role of both executive and end user.
Analysts know how to interpret data and do occasional computing but are not programmers. They may be financial analysts, statisticians, consultants, or database designers. Analysts usually knows some statistics and SQL. These users usually perform three types of data mining activity within a corporate environment: episodic, strategic and continuous data mining.
In episodic mining we look at data from one specific episode such as a specific direct marketing campaign. We may try to understand this data set, or use it for prediction on new marketing campaigns. Episodic mining is usually performed by analysts.
In strategic mining we look at larger sets of corporate data with the intention of gaining an overall understanding of specific measures such as profitability. Hence, a strategic mining exercise may look to answer questions such as: "where do our profits come from?" or "how do our customer segments and product usage patterns relate to each other?"
In continuous mining we try to understand how the world has changed within a given time period and try to gain an understanding of the factors that influence change. For instance, we may ask: "how have sales patterns changed this month?" or "what were the changing sources of customer attrition last quarter?" Obviously continuous mining is an on-going activity and usually takes place once strategic mining has been performed to provide a first understanding of the issues.
Continuous and strategic mining are often directed towards executives and managers, although analysts may help them here. As we shall see later, different technologies are best suited to each of these types of data mining activity.
Copyright (C) 1997, Journal of Data Warehousing, December 1997 |









