|
Data Retention
While in pattern distillation we analyze data, extract patterns and then leave the data behind, in the retention approaches the data is kept for pattern matching. When new data items are presented, they are matched against the previous data set.
A well known example of an approach based on data retention is the "nearest neighbor" method. Here, a data set is kept (usually in memory) for comparison with new data items. When a new record is presented for prediction, the "distance" between it and similar records in the data set is found, and the most similar (or nearest neighbors) are identified.
For instance, given a prospective customer for banking services, the attributes of the prospect are compared with all existing bank customers (e.g., the age and income of the prospect are compared with the age and income of existing customers). Then a set of closest "neighbors" for the prospect are selected (based on closest income, age, etc.).
The term "K-nearest neighbor" is used to mean that we select the top K (e.g. top 10) neighbors for the prospect, as in Figure 3. Next, a closer comparison is performed to select which new product is most suited to the prospect, based on the products used by the top K (e.g., top 10) neighbors.
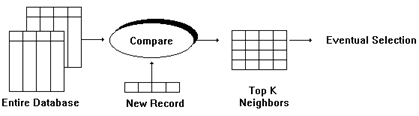
Figure 3.
Of course, it is quite expensive to keep all the data, and hence sometimes just a set of "typical cases" is retained. We may select a set of 100 "typical customers" as the basis for comparison. This is often called case-based reasoning.
Obviously, the key problem here is that of selecting the "typical" customers as cases. If we do not really understand the customers, how can we expect to select the typical cases, and if the customer-base changes, how do we change the typical customers?
Another usually fatal problem for these approaches has to do with databases with a large number of non-numeric values (e.g., many supermarket products or car parts). Since distances between these non-numeric values are not easily computed, some measure of approximation needs to be used -- and this is often hard to come by. And if there are many non-numeric values, there will be too many cases to manage.
Copyright (C) 1997, Journal of Data Warehousing, December 1997 |









